DeepSeek V4のベンチマークリーク、SWE-Bench Verifiedで83.7%の驚異的スコアか
中国のAIスタートアップ、深度求索(DeepSeek)の次期主力モデル「DeepSeek V4」のベンチマークスコアがリークされ、AIコード生成コミュニティで大きな話題を呼んでいる。リーク情報によれば、実践的なコード生成タスクを評価する「SWE-Bench Verified」で83.7%という驚異的なスコアを記録したとされる。これは、現時点で公式リーダーボードの首位を走るAnthropicのClaude 3.5 Opus(約80.9%)を上回る数値だ。しかし、DeepSeek公式はV4の存在も性能も一切発表しておらず、現時点ではあくまで噂の域を出ない。開発者はこの情報を興味深い「予告編」として捉えつつも、公式の発表を冷静に待つ姿勢が求められる。
リークされた「83.7%」という数字の意味
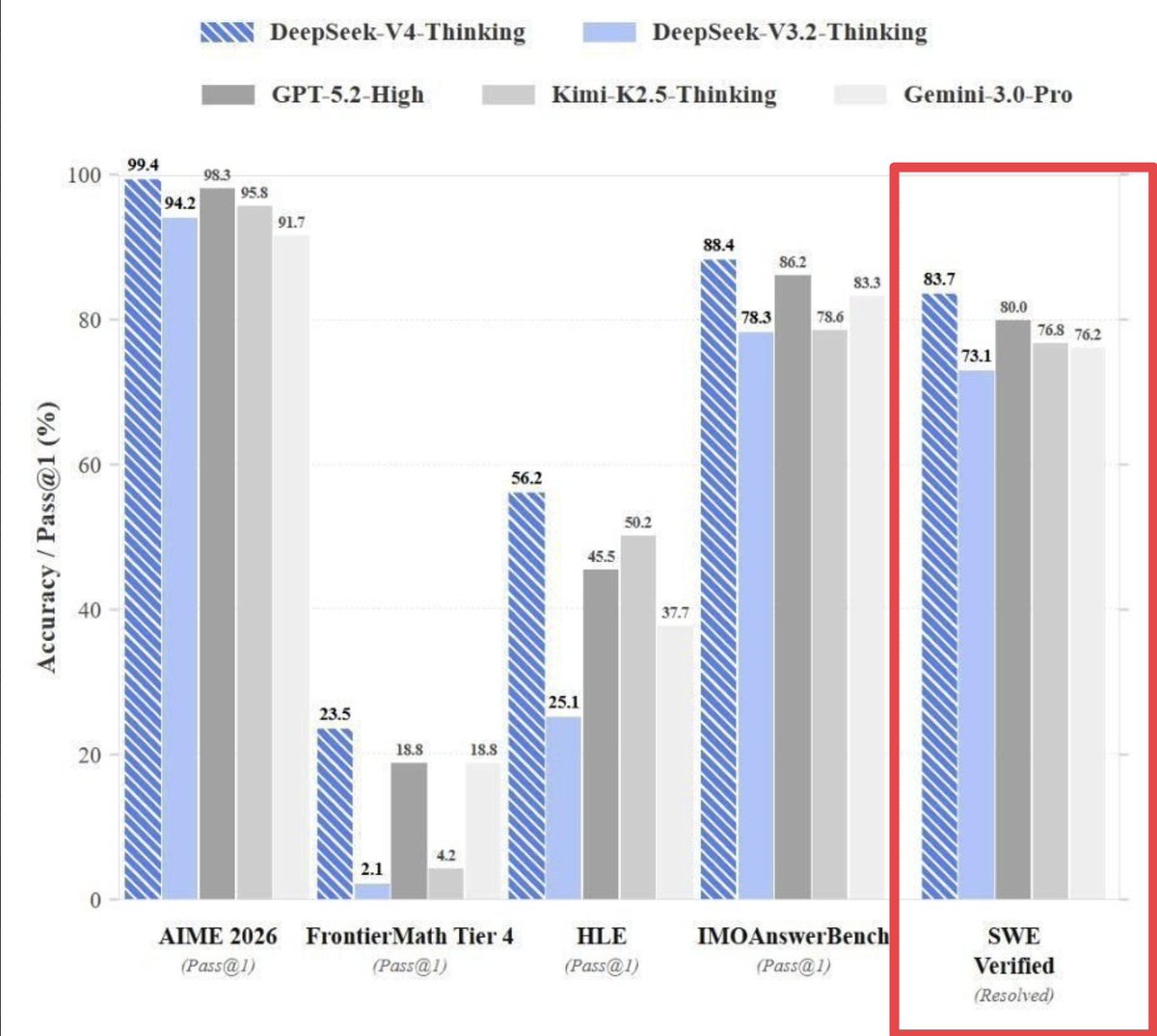
X(旧Twitter)上でリークされた情報の核心は、DeepSeek V4が「SWE-Bench Verified」で83.7%のスコアを達成したという主張だ。SWE-Benchは、GitHubの実在するソフトウェアエンジニアリング課題(issue)を基に、AIモデルがコードを理解し、修正を提案できるかを評価するベンチマークである。特に「Verified」バージョンは、提出された修正が実際にテストケースをパスするかを自動検証するため、モデルの実用的なコーディング能力を測る指標として重視されている。
Scale AIが公開する公式リーダーボード「SWE-bench Pro Public」によれば、2025年3月現在のトップモデルはClaude 3.5 Opusで、そのスコアは約80.9%となっている。リーク情報が正しければ、DeepSeek V4はこの壁を約3ポイント近く上回る計算になる。また、同リークでは比較対象として、DeepSeek V3.2 Thinking(73.1%)、GPT-5.2 High(80.0%)、Kimi K2.5 Thinking(76.8%)、Gemini 3.0 Pro(76.2%)などのスコアが挙げられており、V4が現行の主要モデルを一通り凌駕する可能性が示唆されている。
公式情報との乖離と注意点
このリーク情報を検証する上で最も重要な点は、DeepSeek公式が一切これを認めていないことだ。DeepSeekのAPIドキュメントの更新履歴を確認しても、最新の発表は「DeepSeek-V3.1」に関するものであり、そのSWE-bench Verifiedスコアは66.0%と記載されている。V4の名称はどこにも見当たらない。
さらに、ベンチマークの解釈には注意が必要だ。SWE-Benchには「Pro」と「Verified」という異なる難易度のタスクセットが存在し、スコアに大きな乖離が生じることがある。例えば、あるモデルが「Pro」で高いスコアを出しても、「Verified」では大きく数値が落ちるケースは珍しくない。リーク情報がどの条件での測定結果なのか、詳細なコンテキストが不明である点も、信頼性を判断しにくくしている。
もし本当なら:開発者体験はどう変わるか
仮にDeepSeek V4がリーク通りの性能を持つならば、開発者の日常的なコーディング支援はさらに強力なものになる。SWE-Benchのタスクは、依存関係の更新、複雑なバグの修正、機能追加など、現実の開発現場で遭遇する課題に近い。83.7%というスコアは、多くの場合、AIが単なるコードスニペットを提案するだけでなく、より大きなコードベースの文脈を理解し、適切な修正を一発で生成できる可能性が高いことを意味する。
具体的な使用例を想定すると、例えば、あるオープンソースライブラリで「Python 3.12への互換性を確保するための修正」というissueが立てられた場合、開発者は該当するリポジトリとissue番号をDeepSeek V4に与えるだけで、必要な変更を含むプルリクエスト草案をほぼ完成形で得られるかもしれない。これは、現在のモデルでも可能なタスクではあるが、成功率が飛躍的に向上すれば、コードレビューの前段階の作業効率が劇的に改善される。
コード生成以外の可能性
リーク投稿では「It’s not just coding. Look at the rest:」と続いており、コード生成以外のベンチマークでも優れた結果が出ている可能性がほのめかされている。DeepSeekは以前からマルチモーダル(画像理解)機能には注力せず、純粋なテキストモデルとしての性能追求を標榜してきた。もしV4がコード生成で突出した性能を示すならば、その背後にある高度な推論能力や長文理解能力は、技術文書の要約、システム設計のドラフト作成、あるいは複雑な設定ファイルの生成など、ソフトウェア開発ライフサイクルのより広範な工程にも応用できる潜在力を秘めていると言える。
リーク情報の扱い方と今後の見通し
今回のリークは、AI業界、特に大規模言語モデルの競争が熾烈化していることを如実に物語っている。ベンチマークスコアのリークは、市場の期待を煽り、注目を集めるための一種のマーケティング戦術となる場合も過去には見られた。一方で、単なる推測や誤った情報が流れる可能性も否定できない。
したがって、開発者や技術ディレシジョンメーカーが取るべき態度は明確だ。まず第一に、この情報を以て直ちに技術選定を変更したり、プロジェクトの計画を立てたりするべきではない。第二に、DeepSeekの公式チャンネル(ブログ、APIドキュメント、X公式アカウント)からの発表を注視する。正式な発表があれば、その際にはベンチマークの詳細な設定、評価条件、そして何より価格とアクセシビリティ(API提供の有無、コンテキスト長など)といった実用面での情報がセットで公開されるはずだ。
最終的に、モデルの真価は論文上の数値ではなく、実際のAPIを通じた応答速度、コストパフォーマンス、そして開発者自身のワークフローにどう統合できるかで判断される。DeepSeek V3シリーズがコスト効率の良さで一定の支持を集めてきたことを考えると、仮にV4が登場する場合、その価格設定も性能と同様に注目すべきポイントとなるだろう。
Be First to Comment